apache kafka 개념 정리
kafka는 아마 가장 유명한 스트리밍 플랫폼 중 하나 일 것입니다.
여러모로 사용은 해봤지만 아직 개념적으로 부족한 부분이 많은 듯하여 처음부터 다시 정리해봅니다.
1. Apache Kafka의 간단한 정리

kafka는 분산 스트리밍 플랫폼이라고 합니다.
여기서 분산은 위의 그림처럼 여러 서버 혹은 데이터 센터에 클러스터로 설치 가능하다는 것을 말하며
스트리밍 플랫폼은 데이터 레코드 스트림을 처리할 수 있는 플랫폼이라는 것을 뜻합니다.
쉽게 말하자면 실시간으로 생기는 스트리밍 데이터를 분배할 수 있는 플랫폼 이라고도 할 수 있습니다.
이러한 특성 때문에 대체적으로 실시간 데이터 파이프라인 등 스트리밍 데이터 위주로 사용됩니다.
또한 3가지 특징을 가지고 있습니다.
- 높은 확장성(scalability)과 가용성(availability)
- 데이터 영속성(persistency)
- Pub/Sub 모델을 사용한 데이터 분포
다만 지금 이 글에서는 당장 3가지 특징과 관련된 기능을 다루지는 않습니다.
2. Apache Kafka의 작동 원리
kafka가 뭘 하는 플랫폼인지는 대충 알 것 같습니다. 그러면 이제 이게 어떻게 동작하는지 알아봅시다.
다시 한번 위에서 본 그림을 가져오겠습니다.

데이터를 만들어내서 kafka로 넣어주는 클라이언트는 Producer이며, 받아온 스트림 데이터를 저장하는 곳은 Topic,
저장된 데이터를 kafka에서 받아오는 클라이언트는 Consumer입니다.
여기까지는 어렵지 않습니다. 하지만 여기서 kafka를 좀 더 안쪽까지 들여다봅시다.
Producer - kafka(Topic) 부분입니다.

- Broker : kafka의 서버를 뜻합니다. kafka의 대부분의 기능은 중개인이 거의 다 하는 것이라 보면 됩니다.
- Partition : Topic을 부분을 나눠서 저장하는 것으로 토픽에서 파티션은 서로 다른 중개인에 있을 수도 있습니다.
- offset : 순차적으로 기록된 인덱스 같은 것으로 Cosumer 가 읽었던 위치를 기억할 수 있게 도와줍니다.
각 토픽에는 파티션이 여러 개 있을 수 있습니다.
Producer가 특정 토픽에 데이터를 넣을 때는 적용된 알고리즘에 따라서 파티션에 데이터를 순서대로 넣게 됩니다.
각각의 파티션의 데이터들은 파티션 내의 데이터에 대해 순서를 보장합니다.
다음은 Kafka(Topic) - Consumer 부분을 보겠습니다.
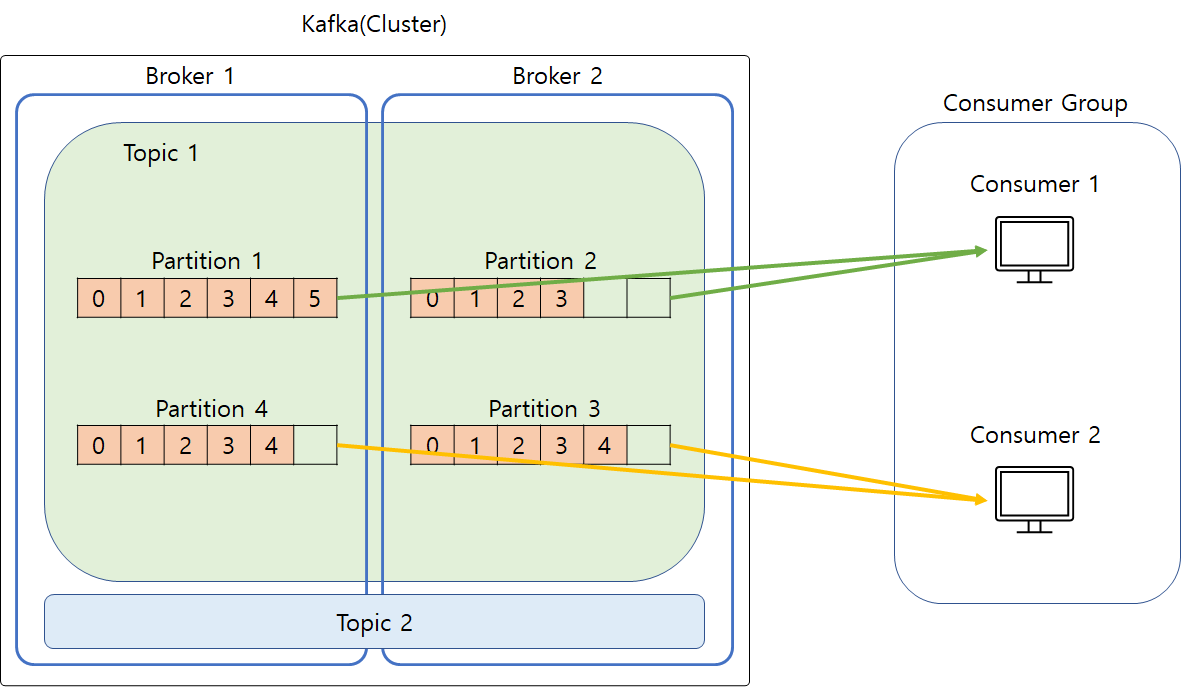
대부분은 Producer 부분과 비슷하나 가장 큰 차이점은 Consumer 가 따로 있는 것이 아니라 Group으로 있는 것입니다.
여러 Producer에서 데이터가 오는 속도보다 Consumer 받는 속도가 느릴 수 있으므로 consumer를 여러 개 만들어
그룹으로 구성한 것입니다. 이렇게 하면 Consumer 마다 정해진 Partition의 데이터를 받아와 데이터를 완성 시킵니다.
다만 이렇게 여러 파티션을 구성하여 데이터를 받아올 때는 원본 데이터와 동일한 순서를 보장하지 않습니다!
하지만 각 파티션에 대해서는 처리 순서를 보장한다는 점 기억해두시면 좋습니다.
또한 위에서 설명드렸던 offset은 Consumer들이 데이터를 읽어올 때 어디까지 읽었는지 확인할 수 있는 용도로
Broker 혹은 Consumer에 에러가 생겨 재시작하더라도 데이터를 다시 중단한 지점에서 받을 수 있도록 해줍니다.
2. Apache Kafka의 사용
이제 kafka의 대략적인 동작 원리를 보았으니 간단하게 kafka의 사용 가능 예시들을 들며 마무리하겠습니다.
- 카카오톡 및 라인 같은 실시간 메시징 서비스
- 여러 대의 서버 로그 처리 시스템
- 실시간으로 데이터가 생기는 모든 것(...)
kafka의 장점은 위에서도 말했듯 실시간 데이터에 장점을 가지고 있습니다. 다만 이것뿐만 아니라
pub/sub 패턴들이 그렇듯 다대다 구조에서도 장점을 보이는데 scale up이 쉽게 가능하므로
실시간으로 데이터가 생기고 이 데이터가 필요한 부분이 많은 경우 강점이 있다고 보시면 될 듯합니다.
대기업 등에서 어떻게 사용하는지 보고 싶으시다면 라인과 링크드인의 예시를 보시면 편하실 겁니다.
참조
What is kafka? | https://youtu.be/aj9CDZm0Glc
카프카(Kafka)의 이해 | https://team-platform.tistory.com/11
카프카(Kafka) | https://sowells.tistory.com/123
LINE에서 Kafka를 사용하는 방법 - 1편 | https://engineering.linecorp.com/ko/blog/how-to-use-kafka-in-line-1/
잘못된 내용이 있다면 언제든 댓글로 달아주시면 감사하겠습니다.